slideflow.norm¶
The slideflow.norm submodule includes tools for H&E stain normalization and augmentation.
Available stain normalization algorithms include:
macenko: Original Macenko paper.
macenko_fast: Modified Macenko algorithm with the brightness standardization step removed.
reinhard: Original Reinhard paper.
reinhard_fast: Modified Reinhard algorithm with the brightness standardization step removed.
reinhard_mask: Modified Reinhard algorithm, with background/whitespace removed.
reinhard_fast_mask: Modified Reinhard-Fast algorithm, with background/whitespace removed.
vahadane: Original Vahadane paper.
augment: HSV colorspace augmentation.
cyclegan: CycleGAN-based stain normalization, as implemented by Zingman et al (PyTorch only)
Overview¶
The main normalizer interface, slideflow.norm.StainNormalizer, offers
efficient numpy implementations for the Macenko, Reinhard, and Vahadane H&E stain normalization algorithms, as well
as an HSV colorspace stain augmentation method. This normalizer can convert
images to and from Tensors, numpy arrays, and raw JPEG/PNG images.
In addition to these numpy implementations, PyTorch-native and Tensorflow-native
implementations are also provided, which offer performance improvements, GPU acceleration,
and/or vectorized application. The native normalizers are found in
slideflow.norm.tensorflow and slideflow.norm.torch, respectively.
The Vahadane normalizer has two numpy implementations available: SPAMS
(vahadane_spams) and sklearn (vahadane_sklearn). By default,
the SPAMS implementation will be used if unspecified (method='vahadane').
Use slideflow.norm.autoselect() to get the fastest available normalizer
for a given method and active backend (Tensorflow/PyTorch).
How to use¶
There are four ways you can use stain normalizers: 1) on individual images, 2) during dataset iteration, 3) during tile extraction, or 4) on-the-fly during training.
Individual images¶
Stain normalizers can be used directly on individual images or batches of images. The Tensorflow and PyTorch-native stain normalizers perform operations on Tensors, allowing you to incoporate stain normalization into an external preprocessing pipeline.
Load a backend-native stain normalizer with autoselect, then transform an image with StainNormalizer.transform(). This function will auto-detect the source image type, perform the most efficient transformation possible, and return normalized images of the same type.
import slideflow as sf
macenko = sf.norm.autoselect('macenko')
image = macenko.transform(image)
You can use slideflow.norm.StainNormalizer.fit() to fit the normalizer to a custom reference image, or use one of our preset fits.
Dataloader pre-processing¶
You can apply stain normalization during dataloader preprocessing by passing the StainNormalizer object to the normalizer argument of either Dataset.tensorflow() or Dataset.torch().
import slideflow as sf
# Get a PyTorch-native Macenko normalizer
macenko = sf.norm.autoselect('macenko')
# Create a PyTorch dataloader that applies stain normalization
dataset = sf.Dataset(...)
dataloader = dataset.torch(..., normalizer=macenko)
Note
GPU acceleration cannot be performed within a PyTorch dataloader. Stain normalizers have a .preprocess() function that stain-normalizes and standardizes a batch of images, so the workflow to normalize on GPU in a custom PyTorch training loop would be:
Get a Dataloader with
dataset.torch(standardize=False, normalize=False)On an image batch, preprocess with
normalizer.preprocess():
# Slideflow dataset
dataset = Project.dataset(tile_px=..., tile_um=...)
# Create PyTorch dataloader
dataloader = dataset.torch(..., standardize=False)
# Get a stain normalizer
normalizer = sf.norm.autoselect('reinhard')
# Iterate through the dataloader
for img_batch, labels in dataloader:
# Stain normalize using GPU
img_batch = img_batch.to('cuda')
with torch.no_grad():
proc_batch = normalizer.preprocess(img_batch)
...
During tile extraction¶
Image tiles can be normalized during tile extraction by using the normalizer and normalizer_source arguments. normalizer is the name of the algorithm. The normalizer source - either a path to a reference image, or a str indicating one of our presets (e.g. 'v1', 'v2', 'v3') - can also be set with normalizer_source.
P.extract_tiles(
tile_px=299,
tile_um=302,
normalizer='reinhard'
)
On-the-fly¶
Performing stain normalization on-the-fly provides greater flexibility, as it allows you to change normalization strategies without re-extracting all of your image tiles.
Real-time normalization can be performed for most pipeline functions - such as model training or feature generation - by setting the normalizer and/or normalizer_source hyperparameters.
from slideflow.model import ModelParams
hp = ModelParams(..., normalizer='reinhard')
If a model was trained using a normalizer, the normalizer algorithm and fit information will be stored in the model metadata file, params.json, in the saved model folder. Any Slideflow function that uses this model will automatically process images using the same normalization strategy.
Performance¶
Slideflow has Tensorflow, PyTorch, and Numpy/OpenCV implementations of stain normalization algorithms. Performance benchmarks for these implementations are given below:
Tensorflow backend |
PyTorch backend |
|
|---|---|---|
macenko |
929 img/s (native) |
881 img/s (native) |
macenko_fast |
1,404 img/s (native) |
1,088 img/s (native) |
reinhard |
1,136 img/s (native) |
3,329 img/s (native) |
reinhard_fast |
4,226 img/s (native) |
4,187 img/s (native) |
reinhard_mask |
1,136 img/s (native) |
3,941 img/s (native) |
reinhard_fast_mask |
4,496 img/s (native) |
4,058 img/s (native) |
vahadane_spams |
0.7 img/s |
2.2 img/s |
vahadane_sklearn |
0.9 img/s |
1.0 img/s |
Contextual Normalization¶
Contextual stain normalization allows you to stain normalize an image using the staining context of a separate image. When the context image is a thumbnail of the whole slide, this may provide slight improvements in normalization quality for areas of a slide that are predominantly eosin (e.g. necrosis or low cellularity). For the Macenko normalizer, this works by determining the maximum H&E concentrations from the context image rather than the image being transformed. For the Reinhard normalizer, channel means and standard deviations are calculated from the context image instead of the image being transformed. This normalization approach can result in poor quality images if the context image has pen marks or other artifacts, so we do not recommend using this approach without ROIs or effective slide-level filtering.
Contextual normalization can be enabled during tile extraction by passing the argument context_normalize=True to slideflow.Dataset.extract_tiles().
You can use contextual normalization when manually using a StainNormalizer object by using the .context() function. The context can either be a slide (path or sf.WSI) or an image (Tensor or np.ndarray).
import slideflow as sf
# Get a Macenko normalizer
macenko = sf.norm.autoselect('macenko')
# Use a given slide as context
slide = sf.WSI('slide.svs', ...)
# Context normalize an image
with macenko.context(slide):
img = macenko.transform(img)
You can also manually set or clear the normalizer context with .set_context() and .clear_context():
# Set the normalizer context
macenko.set_context(slide)
# Context normalize an image
img = macenko.transform(img)
# Remove the normalizer context
macenko.clear_context()
Contextual normalization is not supported with on-the-fly normalization during training or dataset iteration.
Stain Augmentation¶
One of the benefits of on-the-fly stain normalization is the ability to perform dynamic stain augmentation with normalization. For Reinhard normalizers, this is performed by randomizing the channel means and channel standard deviations. For Macenko normalizers, stain augmentation is performed by randomizing the stain matrix target and the target concentrations. In all cases, randomization is performed by sampling from a normal distribution whose mean is the reference fit and whose standard deviation is a predefined value (in sf.norm.utils.augment_presets). Of note, this strategy differs from the more commonly used strategy described by Tellez, where augmentation is performed by randomly perturbing images in the stain matrix space without normalization.
To enable stain augmentation, add the letter ‘n’ to the augment parameter when training a model.
import slideflow as sf
# Open a project
project = sf.Project(...)
# Add stain augmentation to augmentation pipeline
params = sf.ModelParams(..., augment='xryjn')
# Train a model
project.train(..., params=params)
When using a StainNormalizer object, you can perform a combination of normalization and augmention for an image by using the argument augment=True when calling StainNormalizer.transform():
import slideflow as sf
# Get a Macenko normalizer
macenko = sf.norm.autoselect('macenko')
# Perform combination of stain normalization and augmentation
img = macenko.transform(img, augment=True)
To stain augment an image without normalization, use the method StainNormalizer.augment():
import slideflow as sf
# Get a Macenko normalizer
macenko = sf.norm.autoselect('macenko')
# Perform stain augmentation
img = macenko.augment(img)
StainNormalizer¶
- class StainNormalizer(method: str, **kwargs)[source]¶
H&E Stain normalizer supporting various normalization methods.
The stain normalizer supports numpy images, PNG or JPG strings, Tensorflow tensors, and PyTorch tensors. The default
.transform()method will attempt to preserve the original image type while minimizing conversions to and from Tensors.Alternatively, you can manually specify the image conversion type by using the appropriate function. For example, to convert a Tensor to a normalized numpy RGB image, use
.tf_to_rgb().- Parameters:
method (str) – Normalization method. Options include ‘macenko’, ‘reinhard’, ‘reinhard_fast’, ‘reinhard_mask’, ‘reinhard_fast_mask’, ‘vahadane’, ‘vahadane_spams’, ‘vahadane_sklearn’, and ‘augment’.
- Keyword Arguments:
stain_matrix_target (np.ndarray, optional) – Set the stain matrix target for the normalizer. May raise an error if the normalizer does not have a stain_matrix_target fit attribute.
target_concentrations (np.ndarray, optional) – Set the target concentrations for the normalizer. May raise an error if the normalizer does not have a target_concentrations fit attribute.
target_means (np.ndarray, optional) – Set the target means for the normalizer. May raise an error if the normalizer does not have a target_means fit attribute.
target_stds (np.ndarray, optional) – Set the target standard deviations for the normalizer. May raise an error if the normalizer does not have a target_stds fit attribute.
- Raises:
ValueError – If the specified normalizer method is not available.
- Examples
Normalize a numpy image using the default fit.
>>> import slideflow as sf >>> macenko = sf.norm.StainNormalizer('macenko') >>> macenko.transform(image)
Fit the normalizer to a target image (numpy or path).
>>> macenko.fit(target_image)
Fit the normalizer using a preset configuration.
>>> macenko.fit('v2')
Fit the normalizer to all images in a Dataset.
>>> dataset = sf.Dataset(...) >>> macenko.fit(dataset)
Normalize an image and convert from Tensor to numpy array (RGB).
>>> macenko.tf_to_rgb(image)
Normalize images during DataLoader pre-processing.
>>> dataset = sf.Dataset(...) >>> dataloader = dataset.torch(..., normalizer=macenko) >>> dts = dataset.tensorflow(..., normalizer=macenko)
- fit(self, arg1: Dataset | ndarray | str | None, batch_size: int = 64, num_threads: str | int = 'auto', **kwargs) StainNormalizer¶
Fit the normalizer to a target image or dataset of images.
- Parameters:
arg1 – (Dataset, np.ndarray, str): Target to fit. May be a str, numpy image array (uint8), path to an image, or a Slideflow Dataset. If this is a string, will fit to the corresponding preset fit (either ‘v1’, ‘v2’, or ‘v3’). If a Dataset is provided, will average fit values across all images in the dataset.
batch_size (int, optional) – Batch size during fitting, if fitting to dataset. Defaults to 64.
num_threads (Union[str, int], optional) – Number of threads to use during fitting, if fitting to a dataset. Defaults to ‘auto’.
- set_fit(self, **kwargs) None¶
Set the normalizer fit to the given values.
- Keyword Arguments:
stain_matrix_target (np.ndarray, optional) – Set the stain matrix target for the normalizer. May raise an error if the normalizer does not have a stain_matrix_target fit attribute.
target_concentrations (np.ndarray, optional) – Set the target concentrations for the normalizer. May raise an error if the normalizer does not have a target_concentrations fit attribute.
target_means (np.ndarray, optional) – Set the target means for the normalizer. May raise an error if the normalizer does not have a target_means fit attribute.
target_stds (np.ndarray, optional) – Set the target standard deviations for the normalizer. May raise an error if the normalizer does not have a target_stds fit attribute.
- augment(self, image: ndarray | tf.Tensor | torch.Tensor) ndarray | tf.Tensor | torch.Tensor¶
Augment a target image, attempting to preserve the original type.
- Parameters:
image (np.ndarray, tf.Tensor, or torch.Tensor) – Image as a uint8 array. Numpy and Tensorflow images are normalized in W x H x C space. PyTorch images provided as C x W x H will be auto-converted and permuted back after normalization.
- Returns:
Augmented image of the original type (uint8).
- transform(self, image: ndarray | tf.Tensor | torch.Tensor, *, augment: bool = False) ndarray | tf.Tensor | torch.Tensor¶
Normalize a target image, attempting to preserve the original type.
- Parameters:
image (np.ndarray, tf.Tensor, or torch.Tensor) – Image as a uint8 array. Numpy and Tensorflow images are normalized in W x H x C space. PyTorch images provided as C x W x H will be auto-converted and permuted back after normalization.
- Keyword Arguments:
augment (bool) – Transform using stain aumentation. Defaults to False.
- Returns:
Normalized image of the original type (uint8).
- jpeg_to_jpeg(self, jpeg_string: str | bytes, *, quality: int = 100, augment: bool = False) bytes¶
Normalize a JPEG image, returning a JPEG image.
- Parameters:
- Keyword Arguments:
- Returns:
Normalized JPEG image.
- Return type:
- jpeg_to_rgb(self, jpeg_string: str | bytes, *, augment: bool = False) ndarray¶
Normalize a JPEG image, returning a numpy uint8 array.
- png_to_png(self, png_string: str | bytes, *, augment: bool = False) bytes¶
Normalize a PNG image, returning a PNG image.
- png_to_rgb(self, png_string: str | bytes, *, augment: bool = False) ndarray¶
Normalize a PNG image, returning a numpy uint8 array.
- rgb_to_rgb(self, image: ndarray, *, augment: bool = False) ndarray¶
Normalize a numpy array (uint8), returning a numpy array (uint8).
- Parameters:
image (np.ndarray) – Image (uint8).
- Keyword Arguments:
augment (bool) – Transform using stain aumentation. Defaults to False.
- Returns:
Normalized image, uint8, W x H x C.
- Return type:
np.ndarray
- tf_to_rgb(self, image: tf.Tensor, *, augment: bool = False) ndarray¶
Normalize a tf.Tensor (uint8), returning a numpy array (uint8).
- Parameters:
image (tf.Tensor) – Image (uint8).
- Keyword Arguments:
augment (bool) – Transform using stain aumentation. Defaults to False.
- Returns:
Normalized image, uint8, W x H x C.
- Return type:
np.ndarray
- tf_to_tf(self, image: Dict | tf.Tensor, *args: Any, augment: bool = False) Tuple[Dict | tf.Tensor, ...]¶
Normalize a tf.Tensor (uint8), returning a numpy array (uint8).
- Parameters:
image (tf.Tensor, Dict) – Image (uint8) either as a raw Tensor, or a Dictionary with the image under the key ‘tile_image’.
args (Any, optional) – Any additional arguments, which will be passed and returned unmodified.
- Keyword Arguments:
augment (bool) – Transform using stain aumentation. Defaults to False.
- Returns:
A tuple containing the normalized tf.Tensor image (uint8, W x H x C) and any additional arguments provided.
- torch_to_torch(self, image: Dict | torch.Tensor, *args, augment: bool = False) Tuple[Dict | torch.Tensor, ...]¶
Normalize a torch.Tensor (uint8), returning a numpy array (uint8).
- Parameters:
image (torch.Tensor, Dict) – Image (uint8) either as a raw Tensor, or a Dictionary with the image under the key ‘tile_image’.
args (Any, optional) – Any additional arguments, which will be passed and returned unmodified.
- Keyword Arguments:
augment (bool) – Transform using stain aumentation. Defaults to False.
- Returns:
A tuple containing
np.ndarray: Normalized torch.Tensor image, uint8 (channel dimension matching the input image)
args (Any, optional): Any additional arguments provided, unmodified.
Example images¶
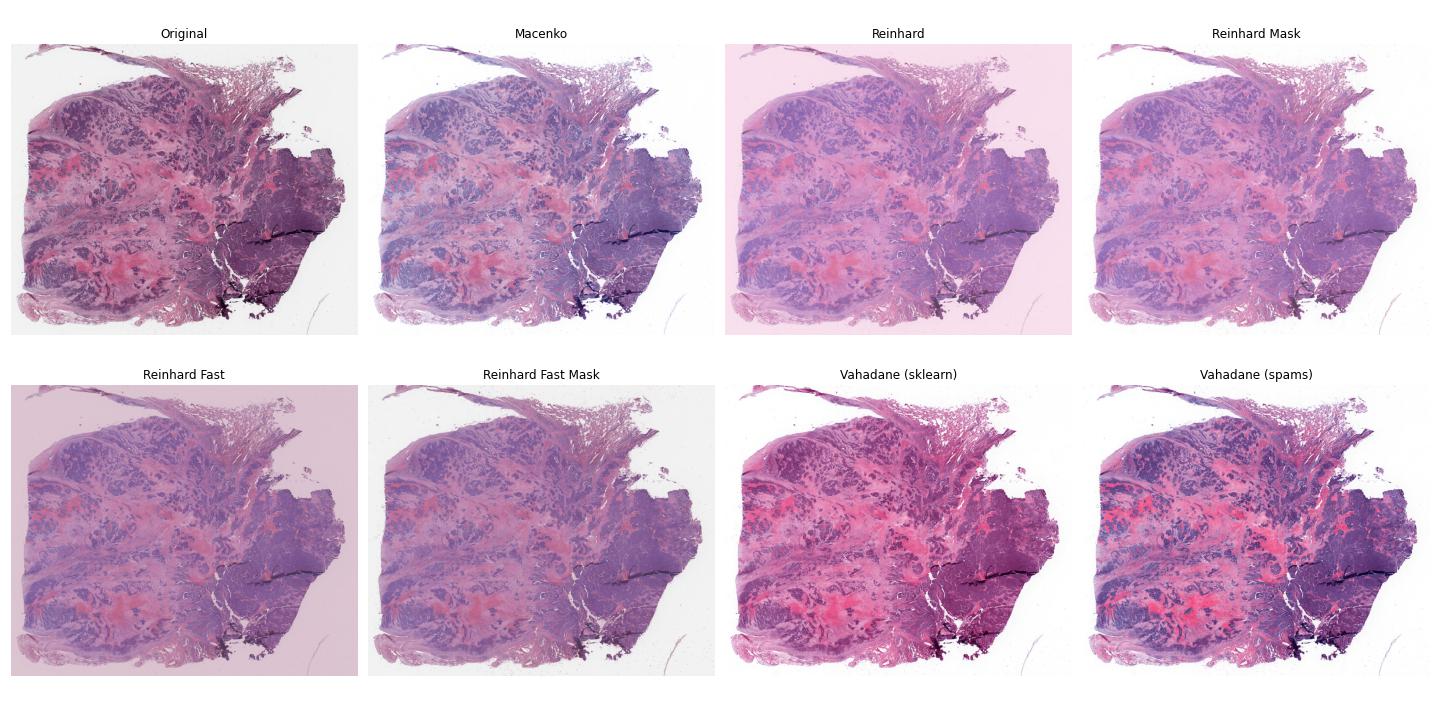
Comparison of normalizers applied to a whole-slide image.¶
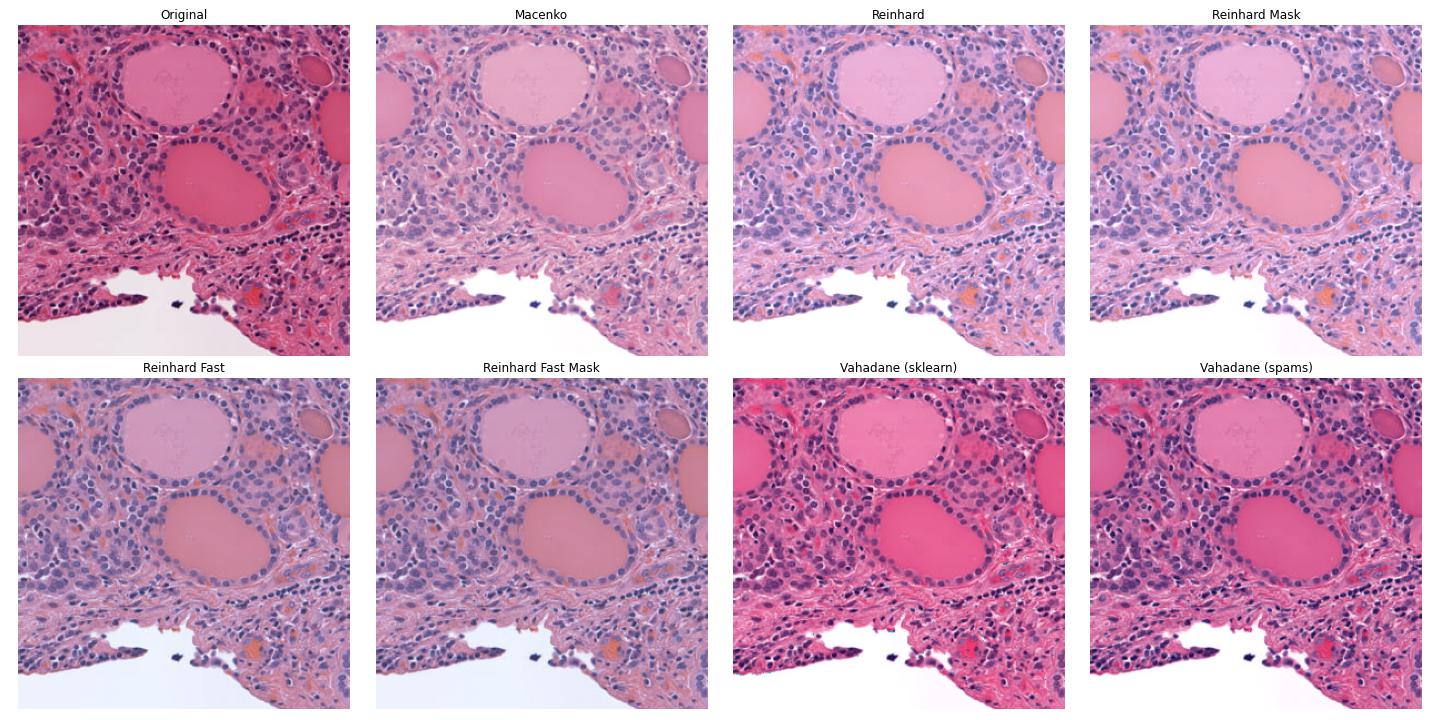
Comparison of normalizers applied to an image tile.¶
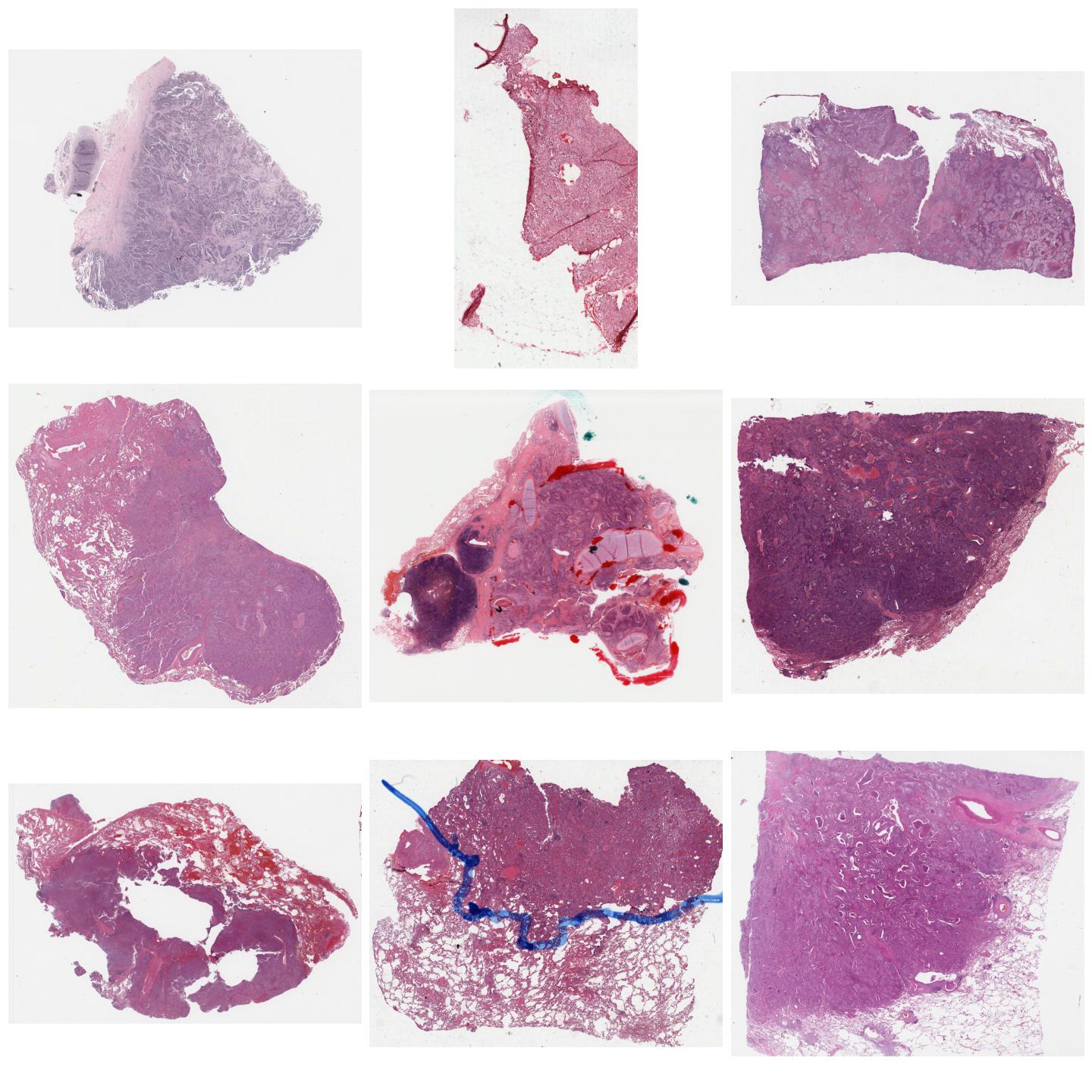
Unnormalized whole-slide images.¶
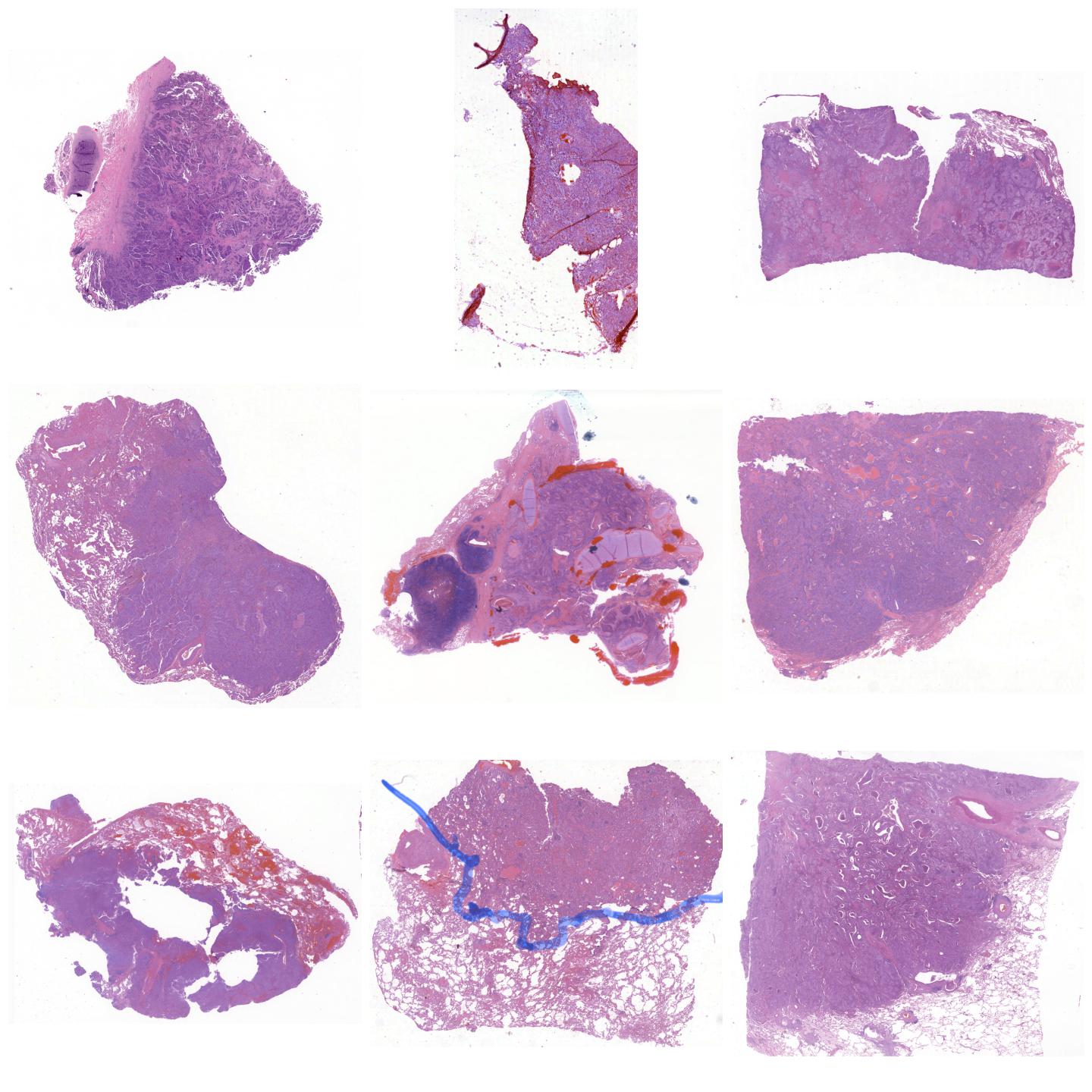
Whole-slide images normalized with Reinhard, fit to preset “v1” (default)¶
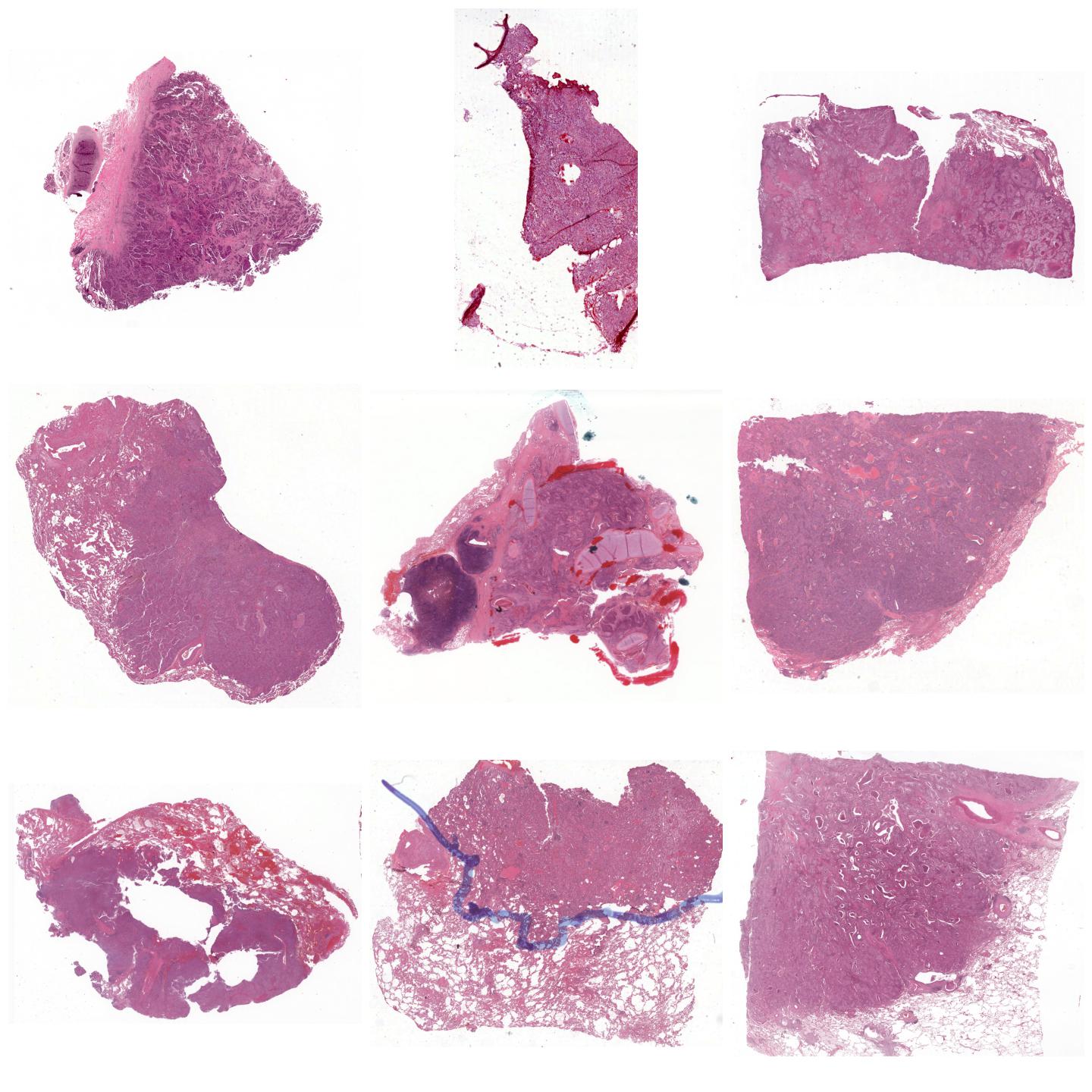
Whole-slide images normalized with Reinhard, fit to preset “v2”¶
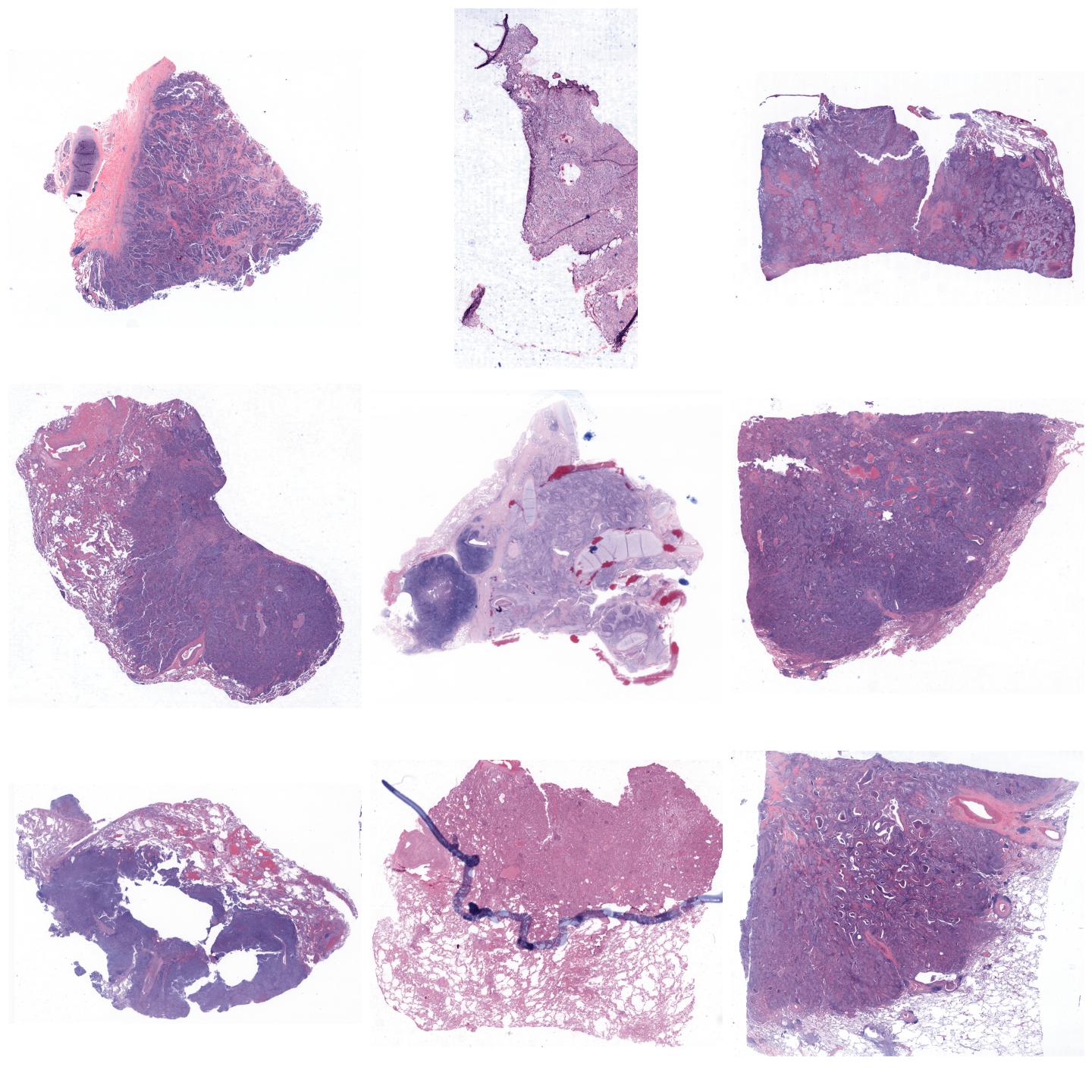
Whole-slide images normalized with Macenko, fit to preset “v1” (default)¶
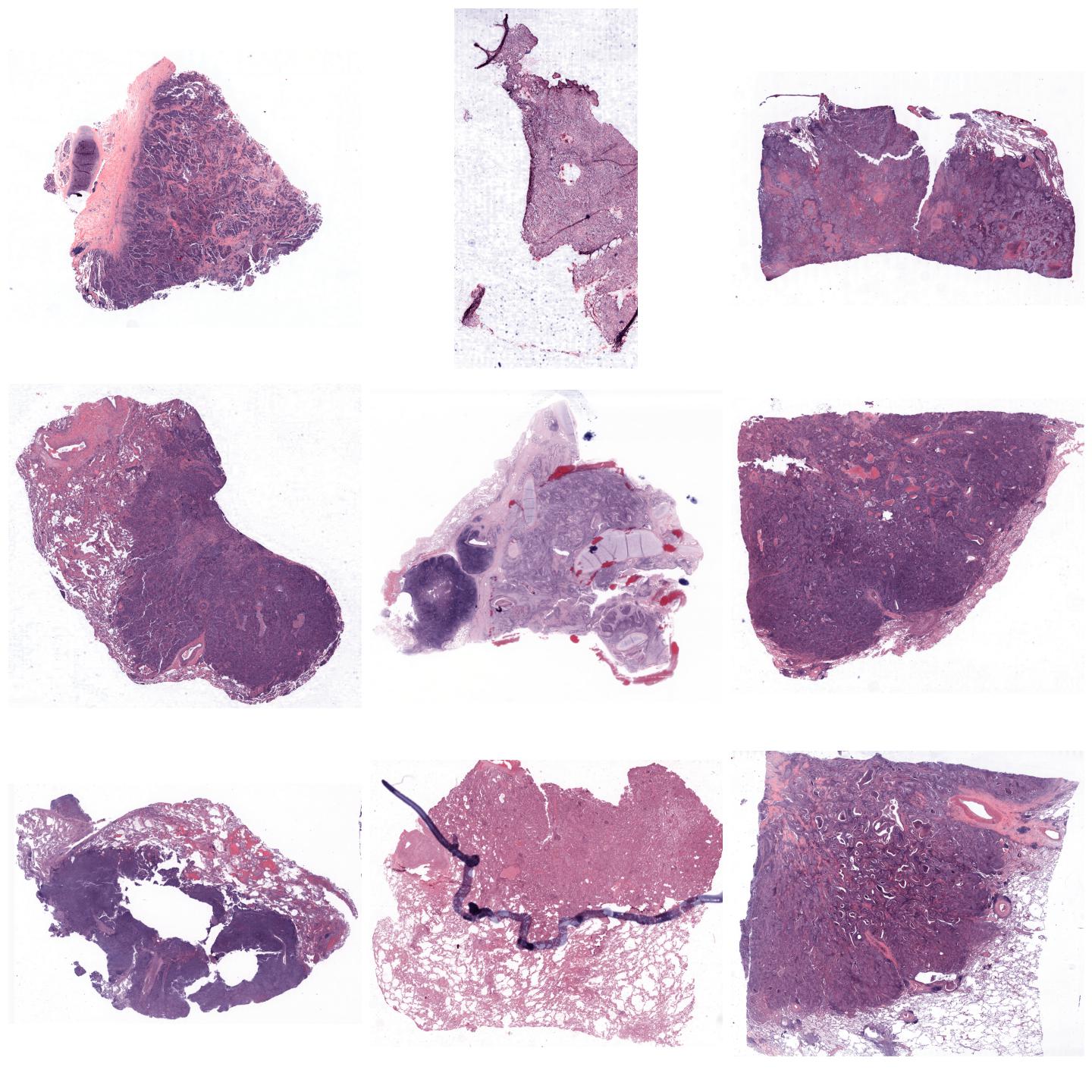
Whole-slide images normalized with Macenko, fit to preset “v2”¶
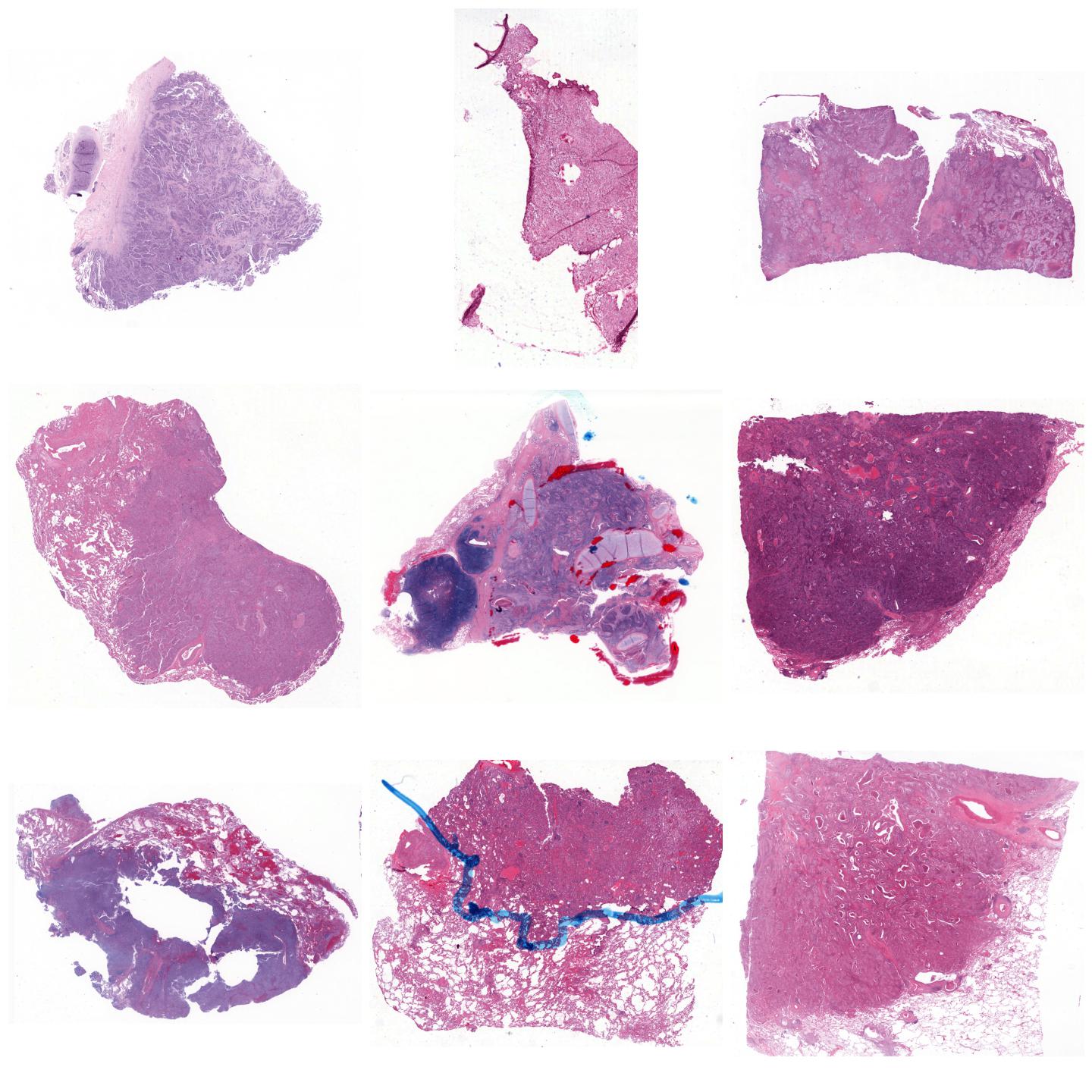
Whole-slide images normalized with Vahadane, fit to preset “v1” (default)¶
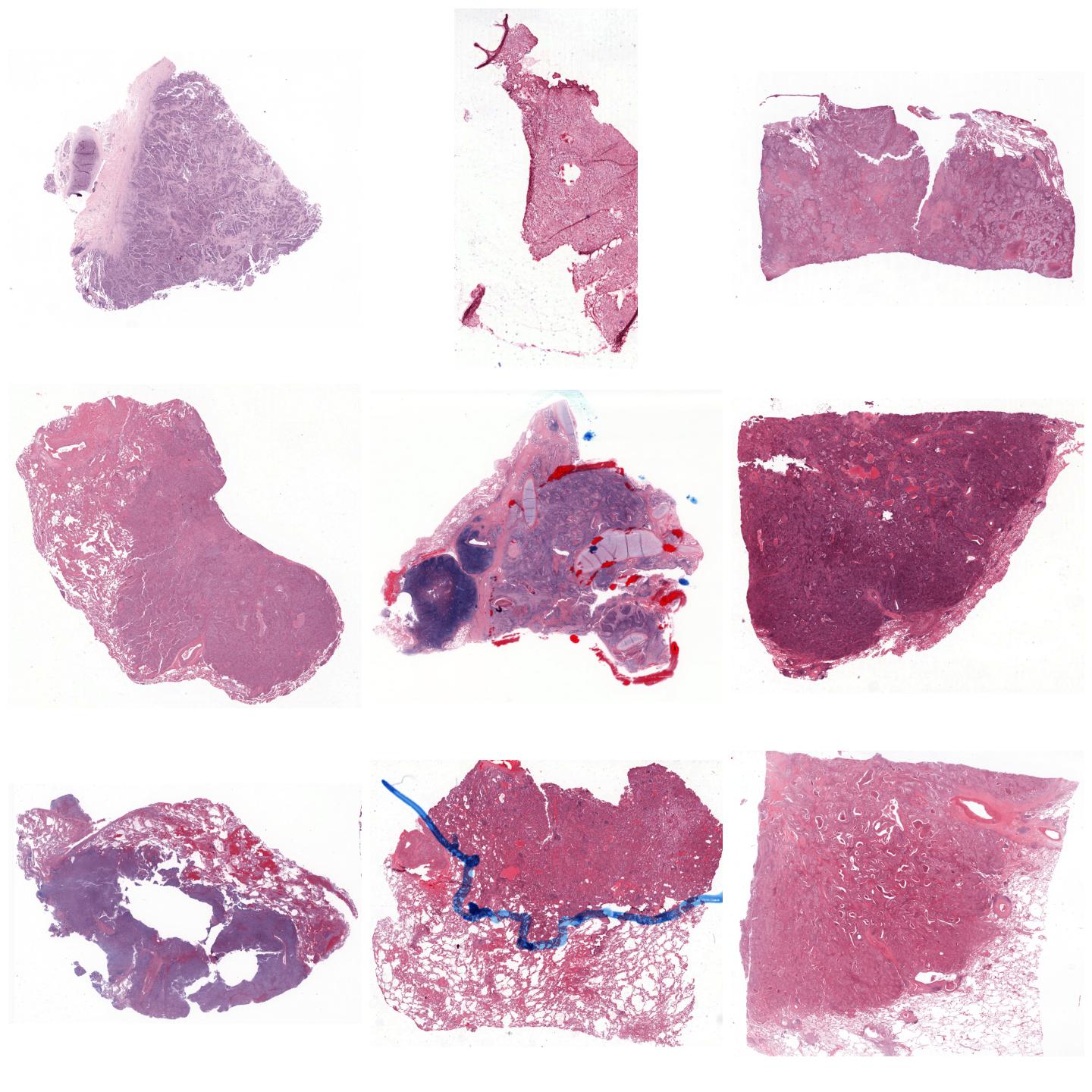
Whole-slide images normalized with Vahadane, fit to preset “v2”¶
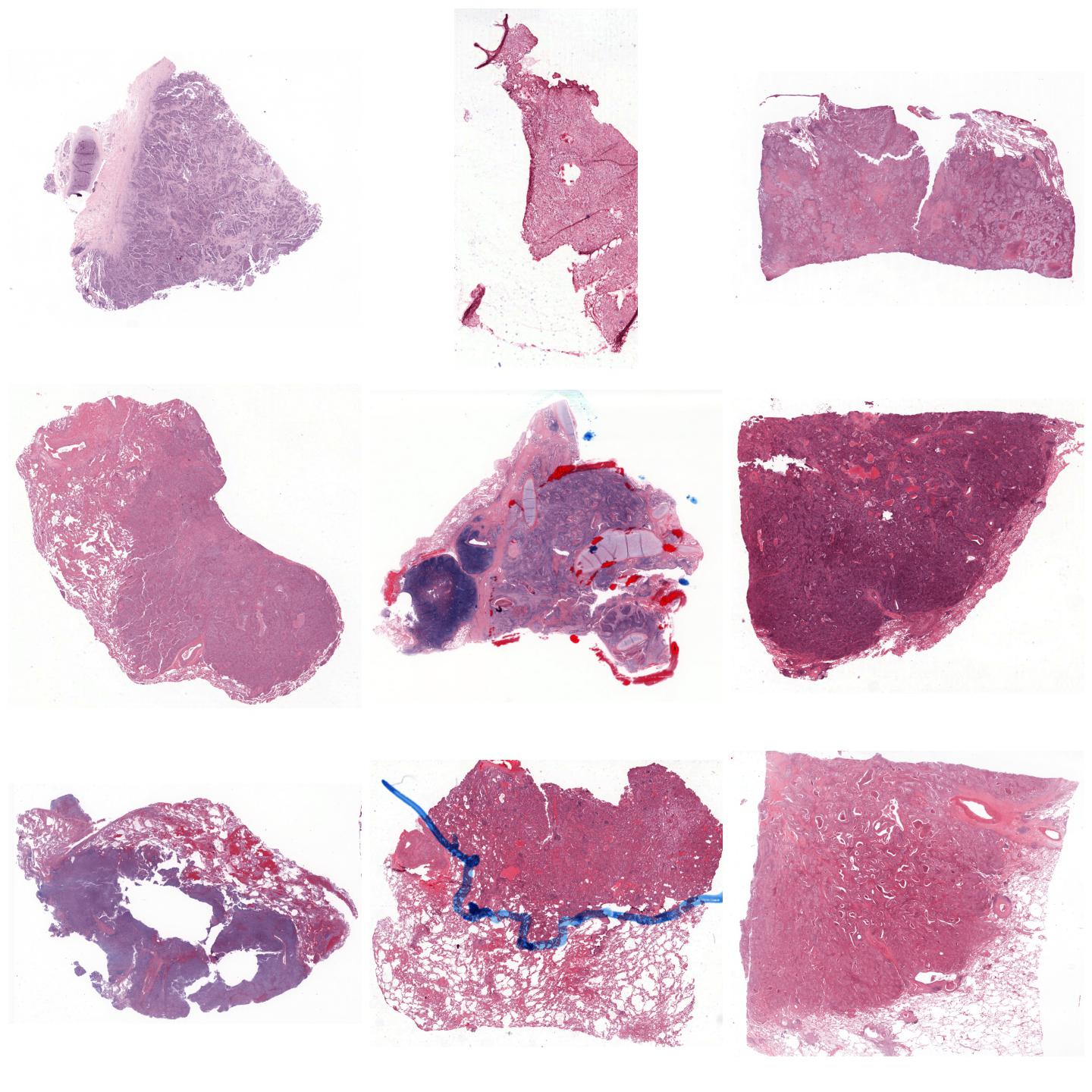
Whole-slide images normalized with Vahadane (SPAMS), fit to preset “v1” (default)¶
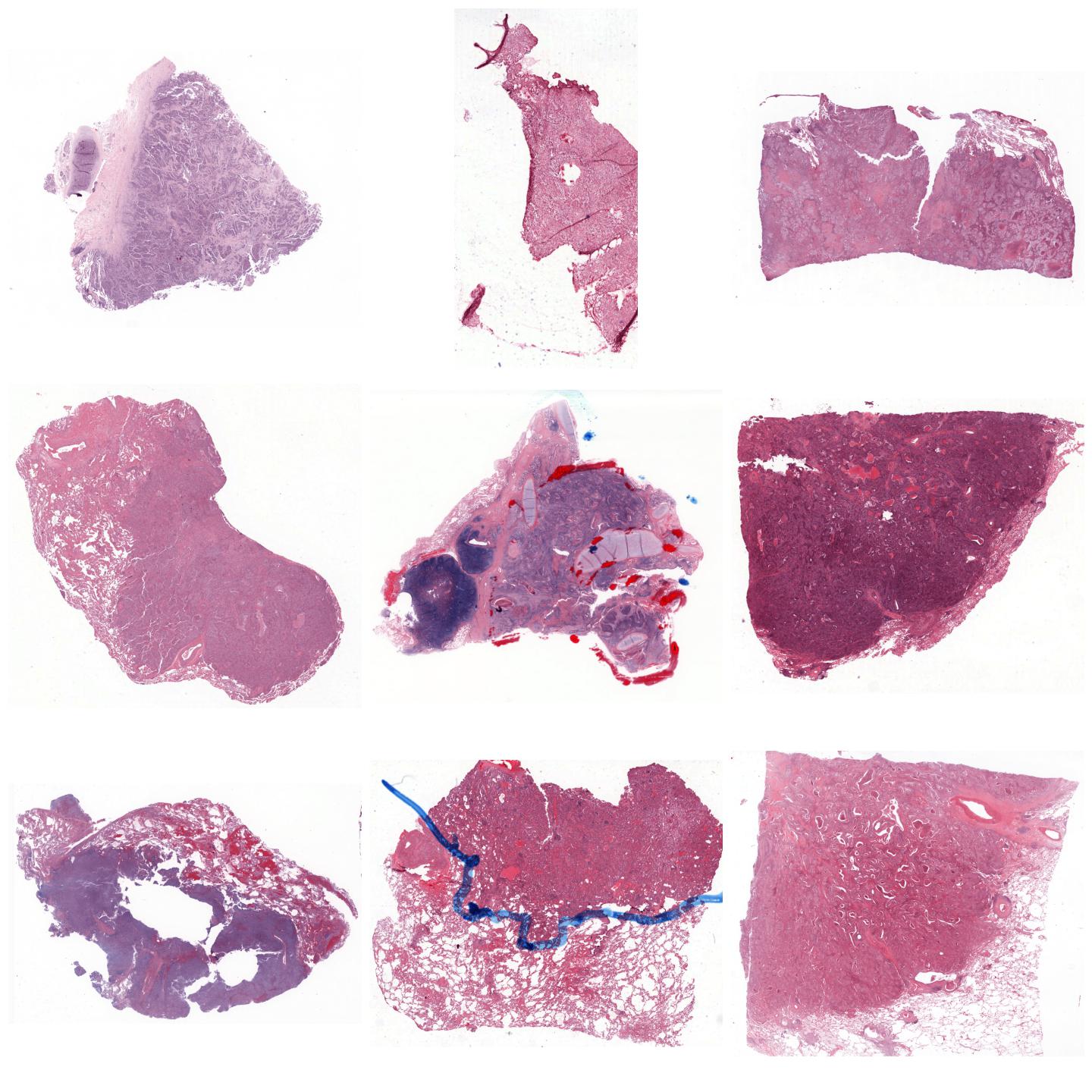
Whole-slide images normalized with Vahadane (SPAMS), fit to preset “v2”¶
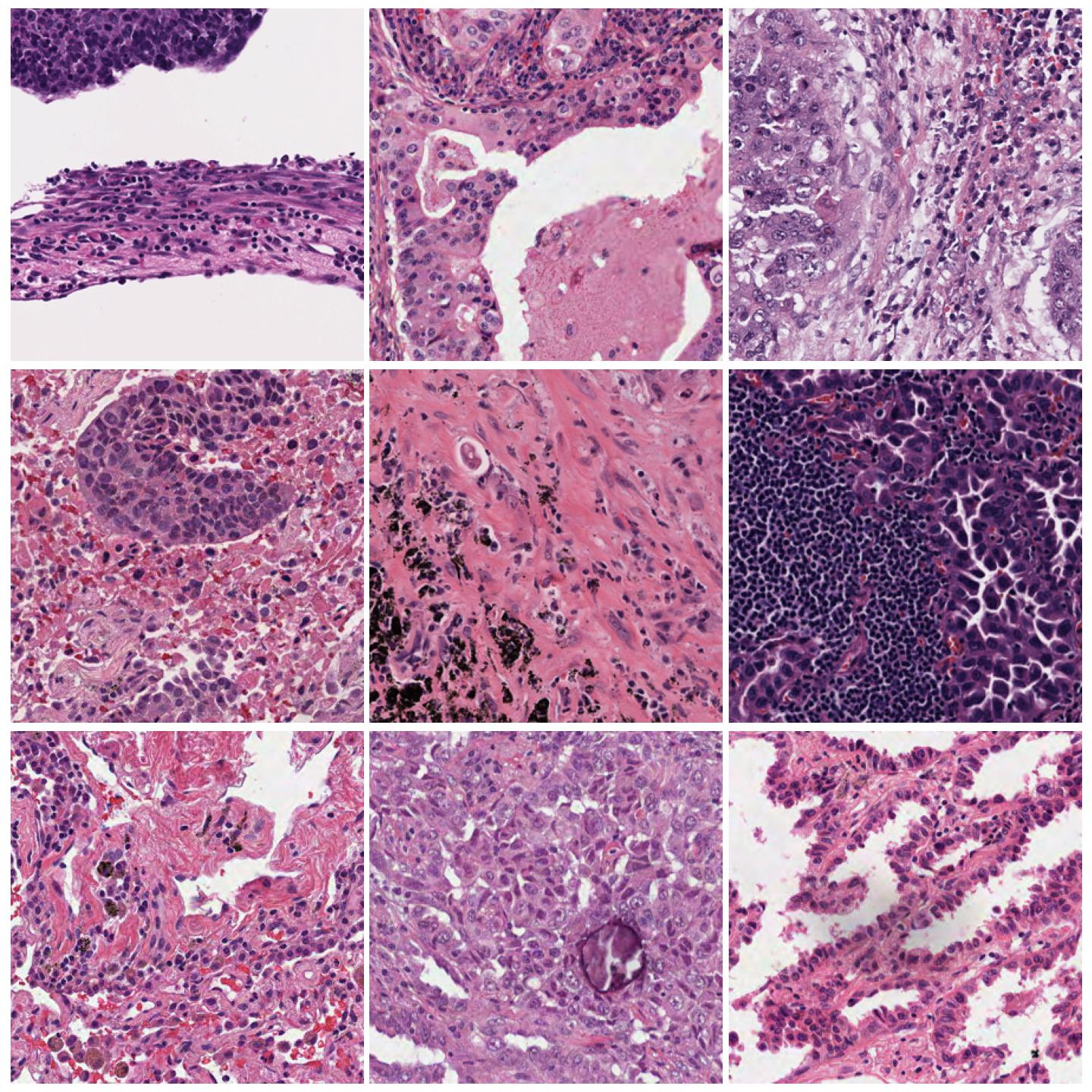
Unnormalized image tiles.¶
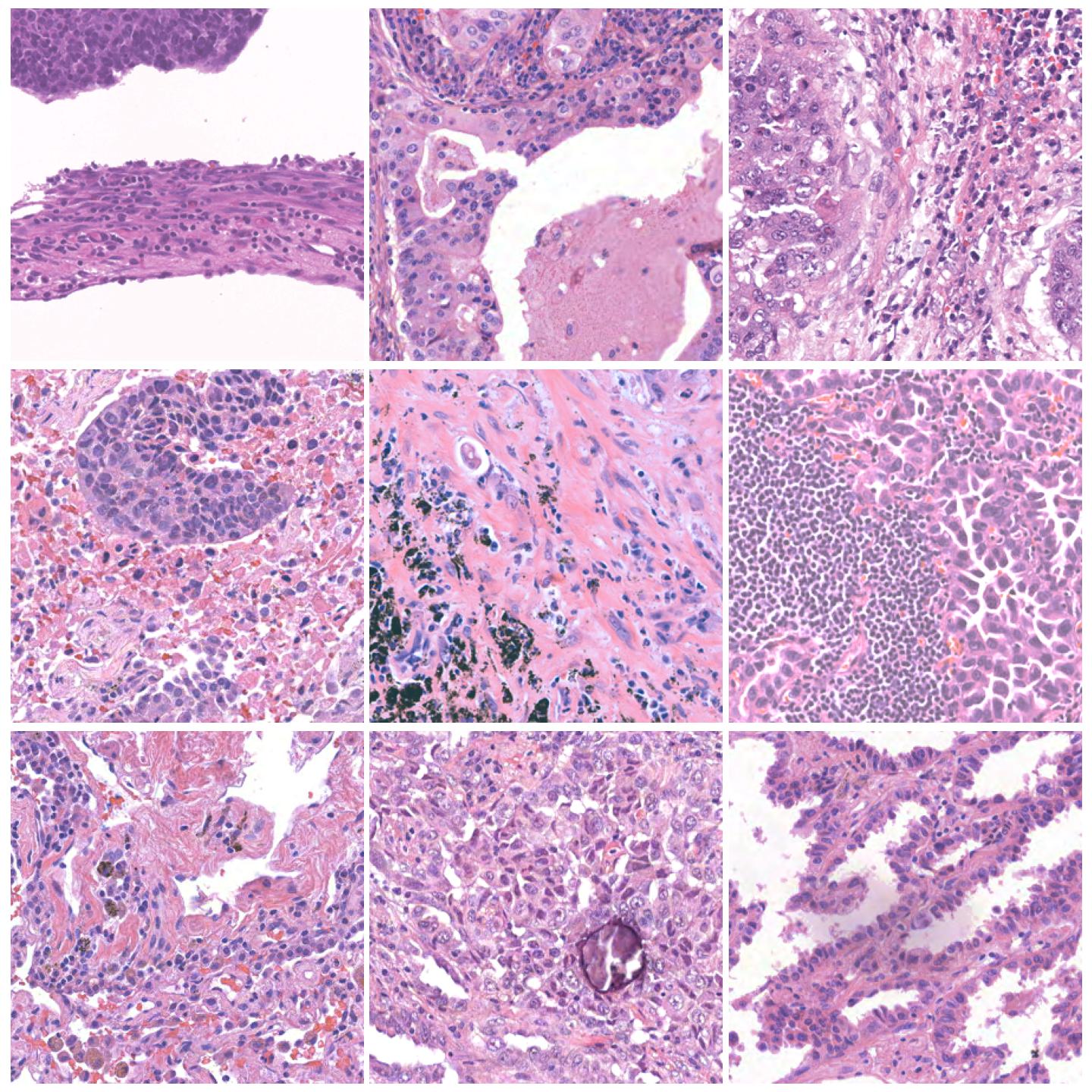
Image tiles normalized with Reinhard Mask, fit to preset “v1” (default)¶
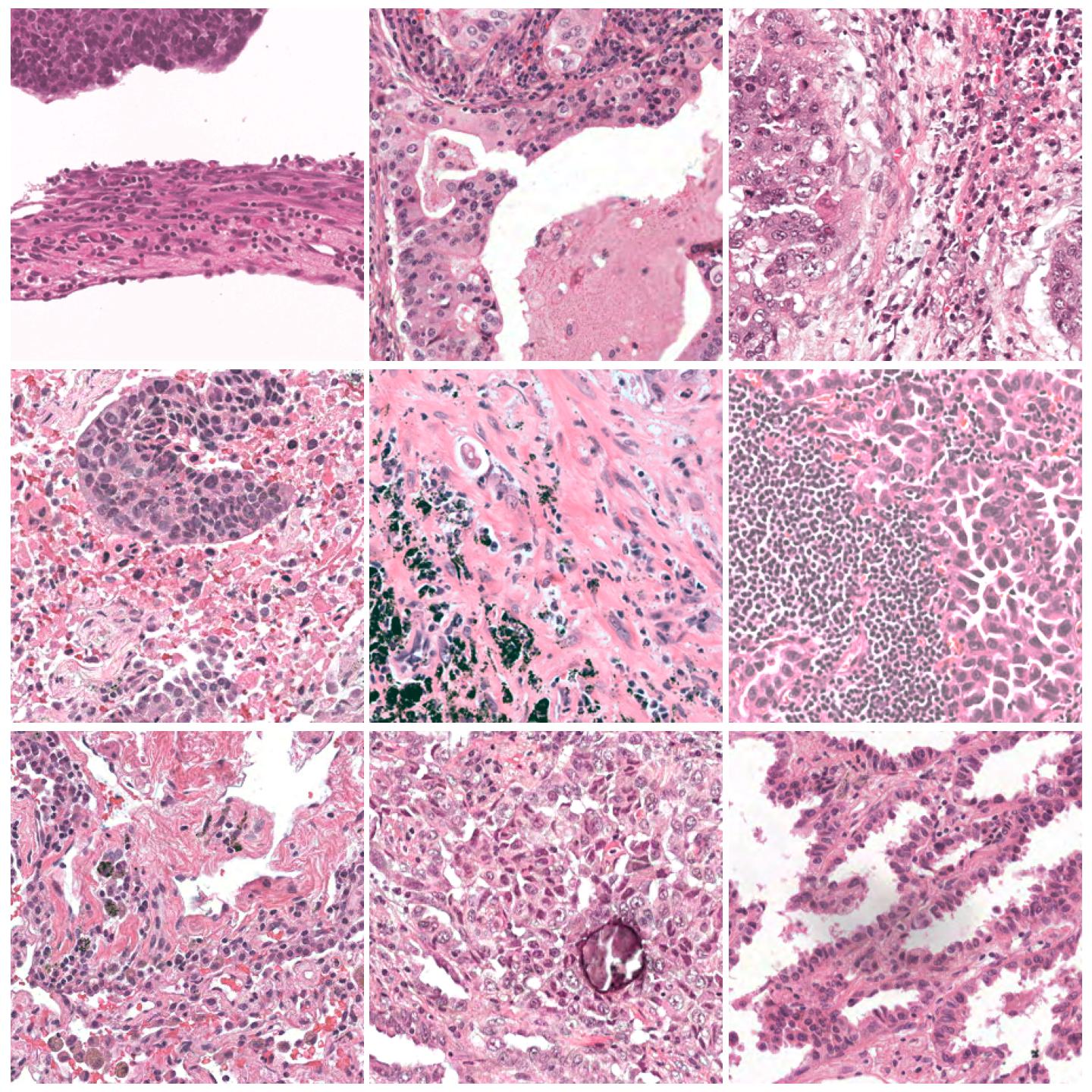
Image tiles normalized with Reinhard Mask, fit to preset “v2”¶
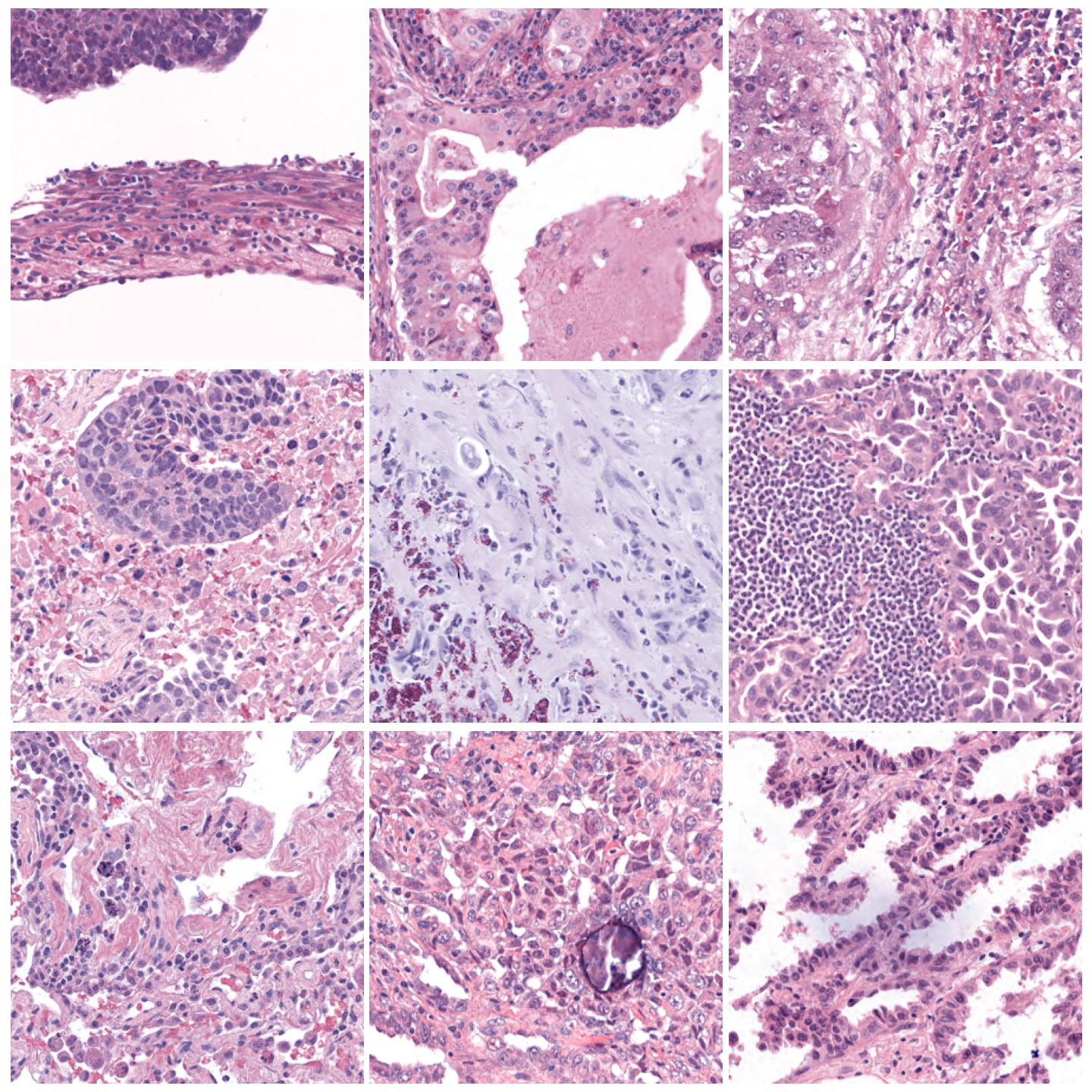
Image tiles normalized with Macenko, fit to preset “v1” (default)¶
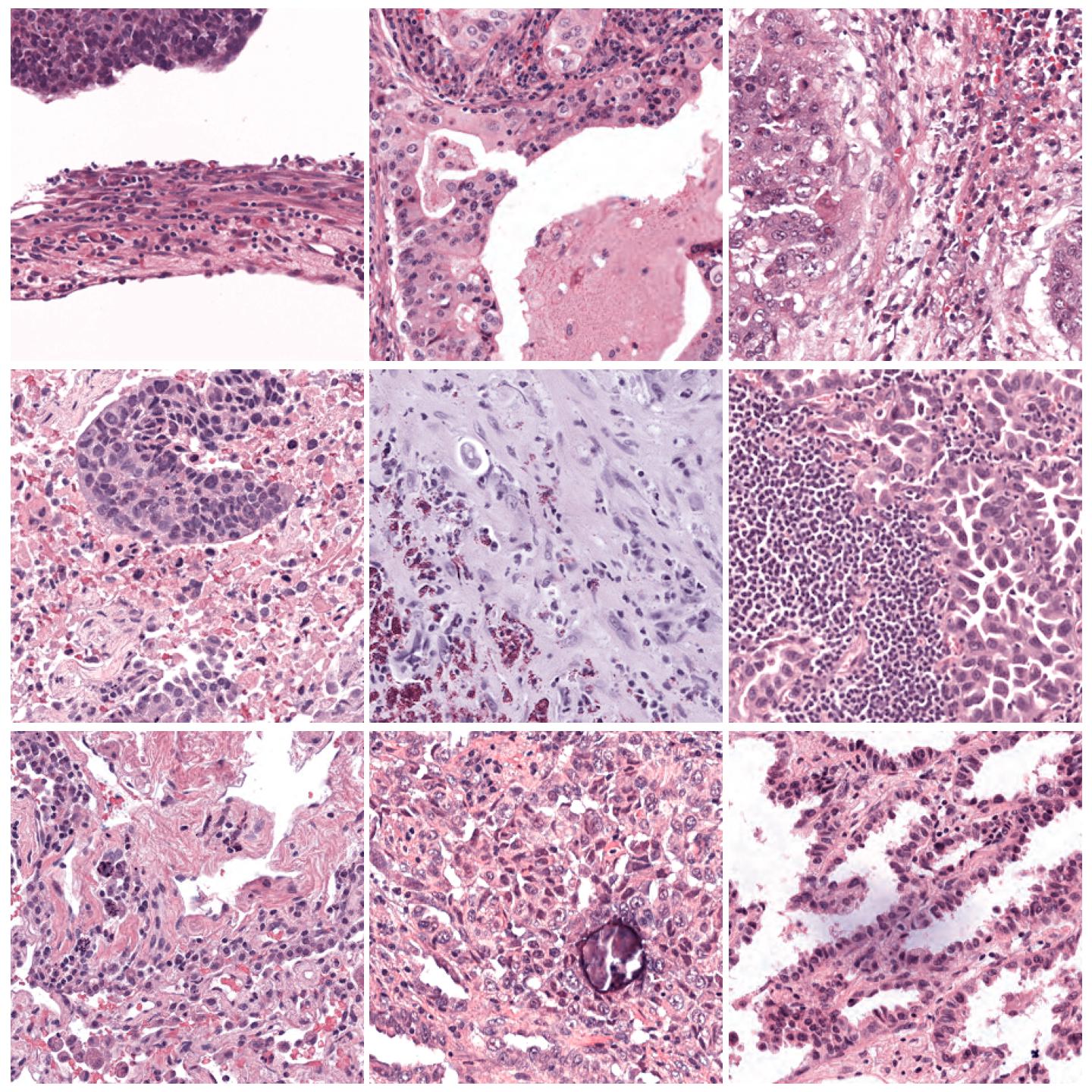
Image tiles normalized with Macenko, fit to preset “v2”¶
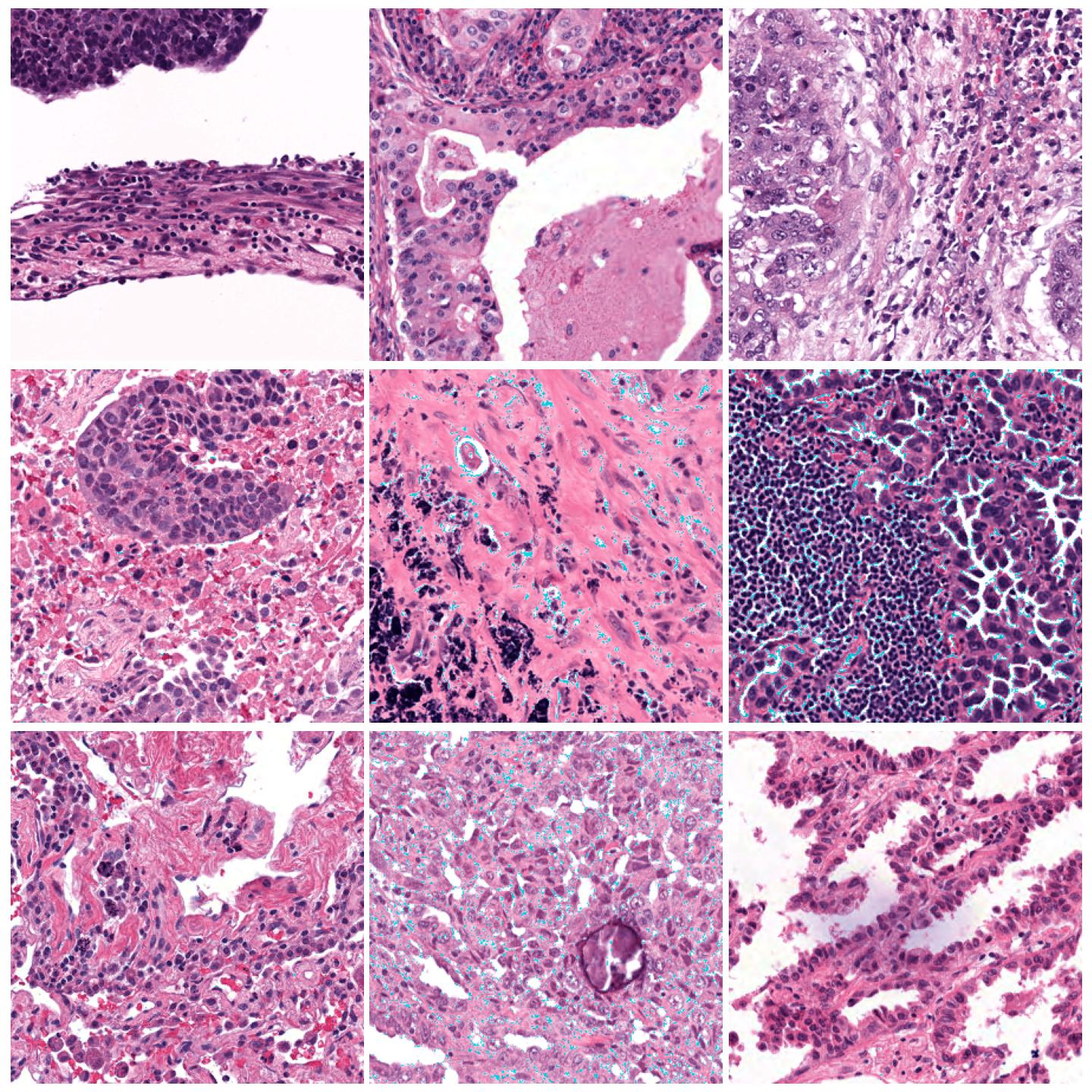
Image tiles normalized with Vahadane, fit to preset “v1” (default)¶
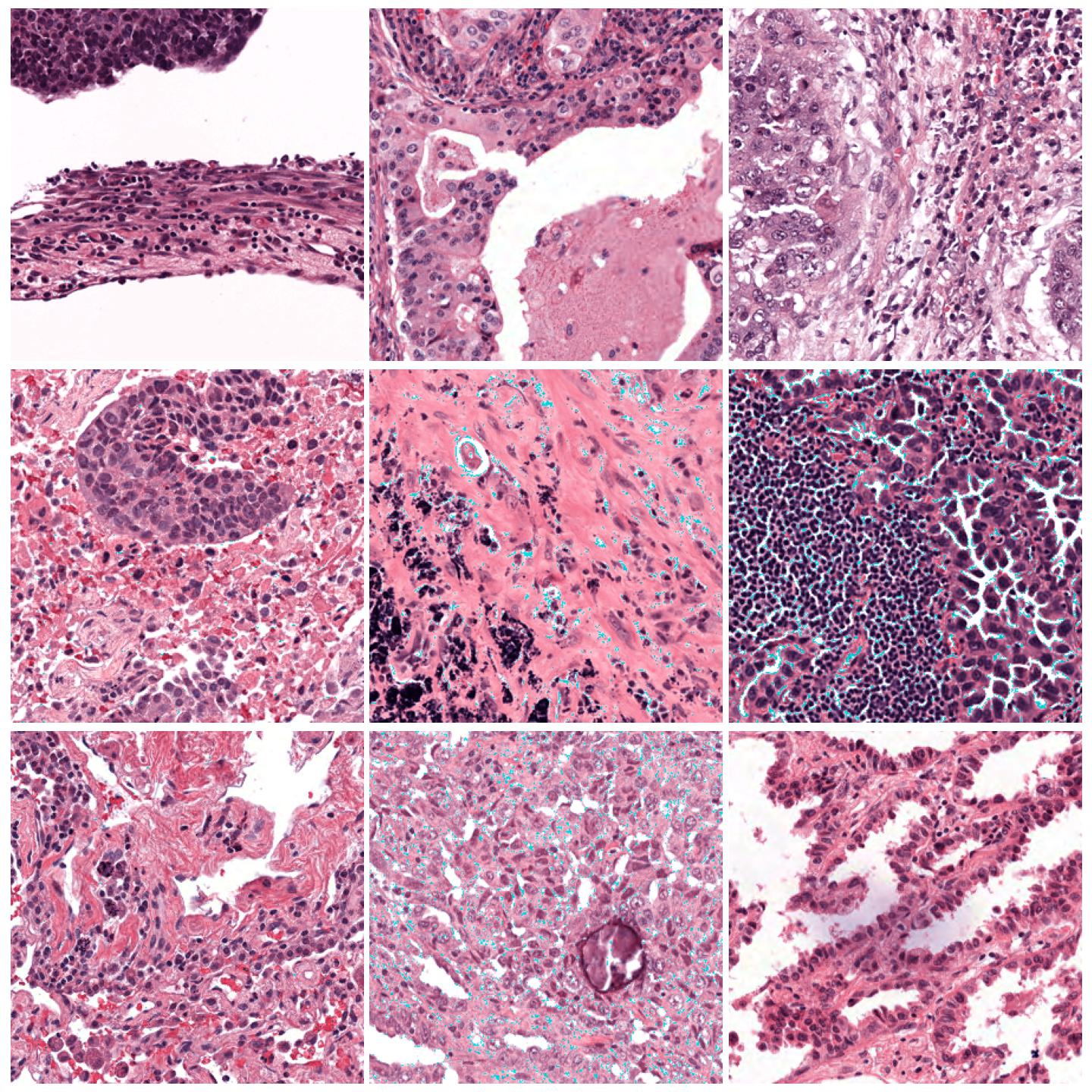
Image tiles normalized with Vahadane, fit to preset “v2”¶
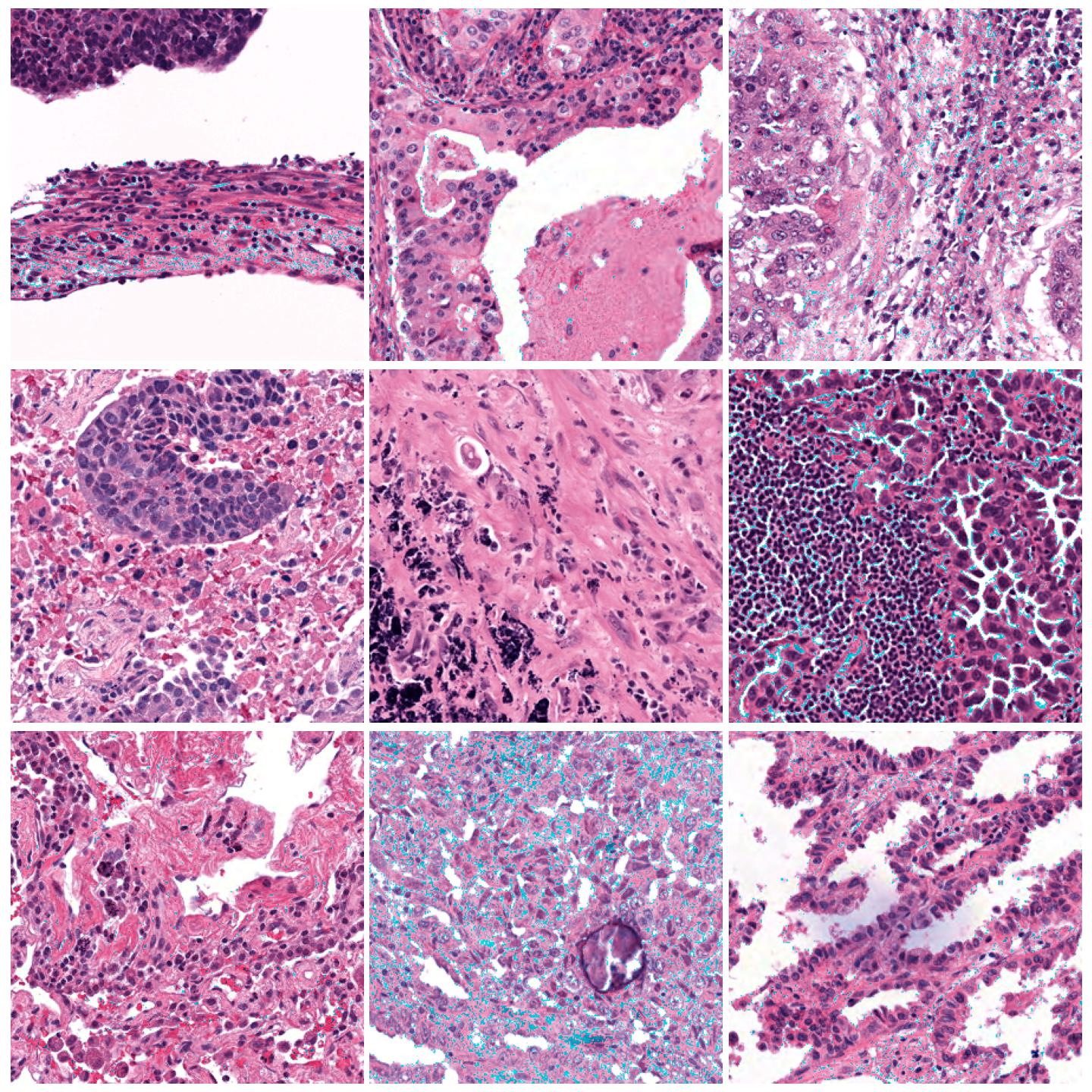
Image tiles normalized with Vahadane (SPAMS), fit to preset “v1” (default)¶
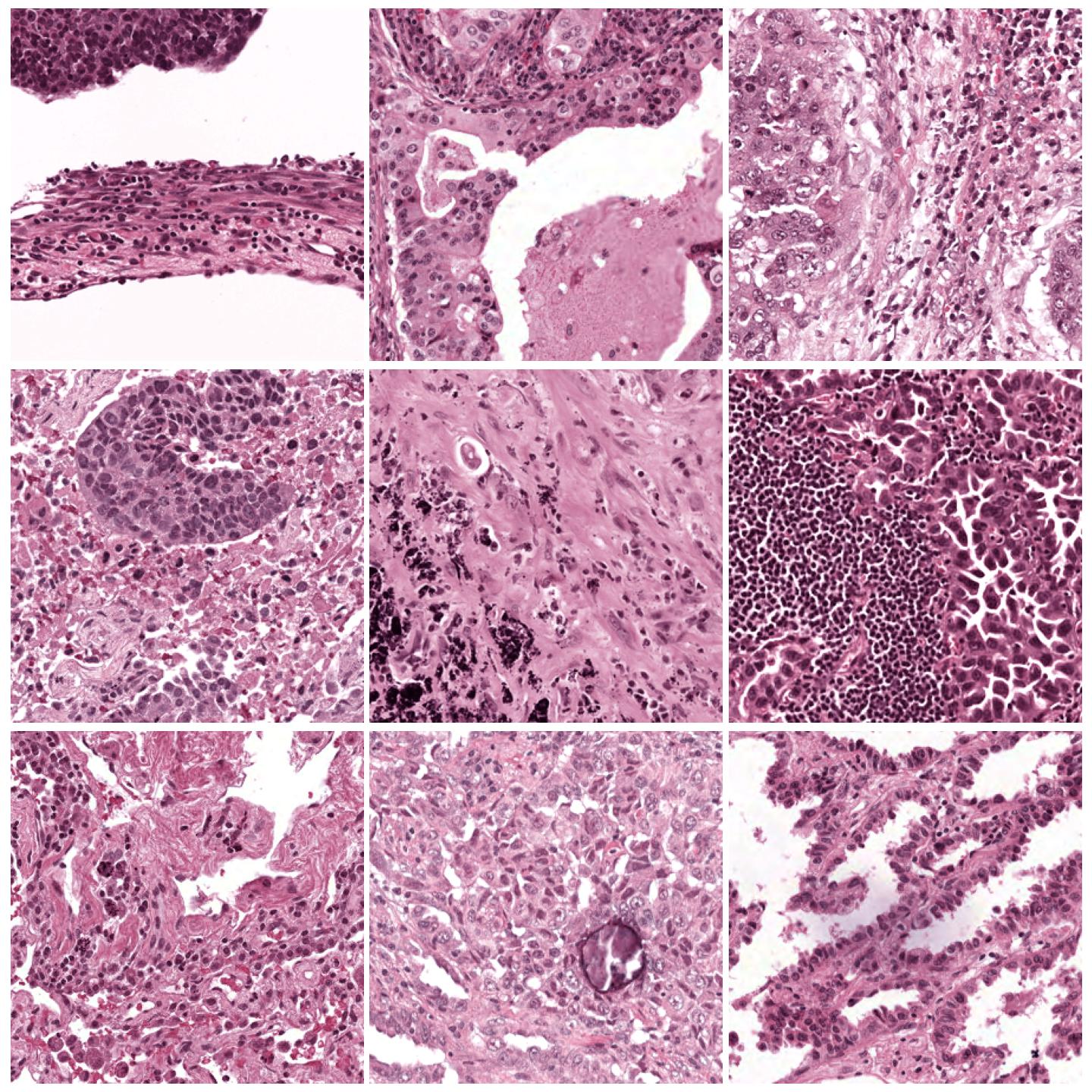
Image tiles normalized with Vahadane (SPAMS), fit to preset “v2”¶